Working with any ML project is like raising a toddler. At first, you’re just trying to figure out how to keep it from breaking everything in the house. Then, you spend some time teaching it how to do simple tasks and when it has learned to be self-sufficient, you sit back and watch proudly as it successfully goes about it’s life. This doesn’t mean you can just leave it as it is, you need to continue to take care of it for a long time to ensure it thrives.
Working on any machine learning project is pretty much the same, except for changing the diapers maybe.
Now I did not come from a machine learning background, apart from studying it in one of my semesters in college, nothing about it seemed like my cup of tea. But as faith would have it, in my first corporate gig ever, I found myself surrounded by everything machine learning.
So I had to learn how to raise toddlers build and work with machine learning models from the get-go. Thanks to my amazing peers at Thoucentric who helped me understand the ins and outs of this domain. As I write this post, reflecting on my notes in Notion, I realize how much I have learned and grown from someone who previously had limited knowledge about this field to designing systems that incorporate cutting-edge machine learning models.
To start off. From whatever I have learned so far one of the key principles of Machine Learning has to be “garbage in, garbage out”, what that means is no matter what problem you’re trying to solve with Machine Learning or what fancy algorithms you’re trying to implement, data still remains the foundation of any successful machine learning project. And as with everything, there’s a relevant XKCD comic for this.

While an ML project shares many similarities with traditional software development projects, it also has specific intricacies unique to the field of ML. Generally, an ML project will consist of the following steps:
- Data Collection: Gathering all the data that is required for training a machine learning model.
- Data Preparation: Cleaning the data, handling missing values, and splitting the data into training and testing sets.
- Model Training: Selecting an appropriate algorithm and training a model on the training data.
- Model Evaluation: Evaluating the performance of the model on the testing data to ensure it is accurate and reliable.
- Model Deployment: Deploying the model to a production environment where it can be used to make predictions on new data.
- Monitoring and Maintenance: Monitoring the model’s performance over time and updating it as needed to ensure it continues to perform at a high level.
Each of these steps is crucial and requires careful attention to detail to ensure the final product is accurate, reliable, and effective. Any discrepancies in data at any point in the process can lead to larger issues in downstream applications.
To better understand this process, we have this diagram which provides a clear idea of the entire ML Lifecyle, the sequence of steps involved and the interdependencies between them.
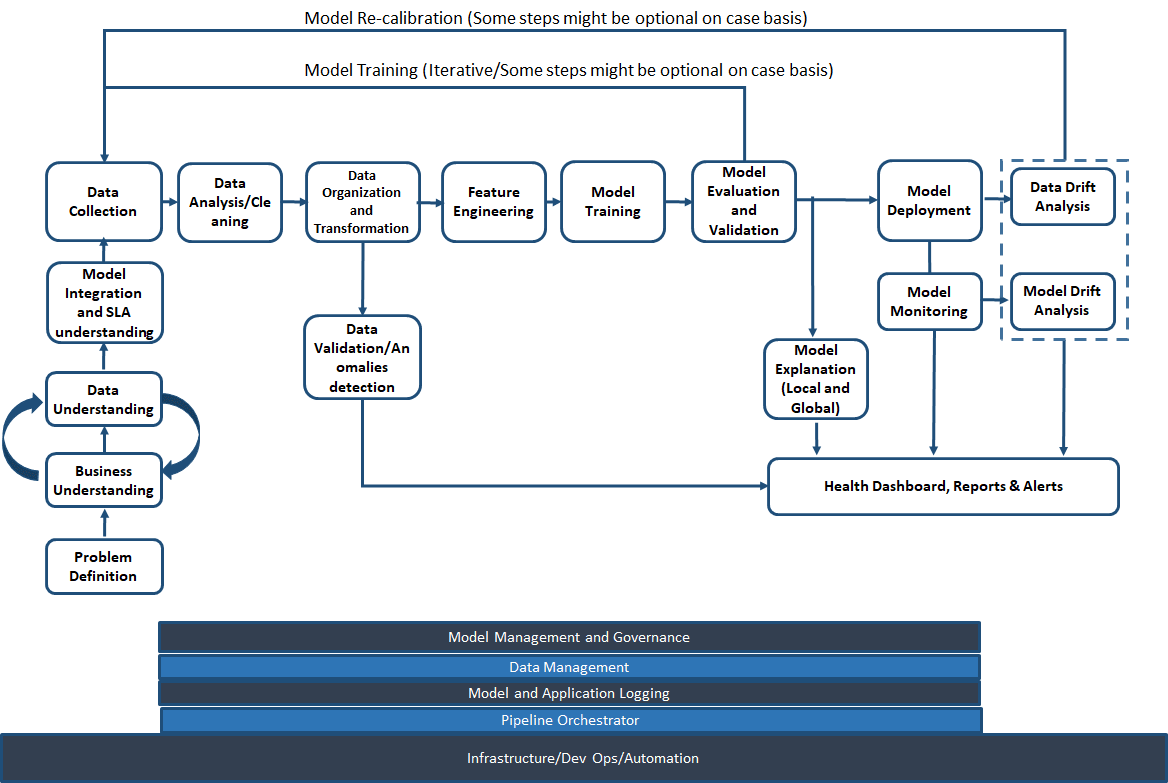
By analyzing the diagram, we can identify two main workflows commonly used in enterprise AI today. The first is the DevOps workflow, which focuses on resource management, infrastructure, orchestration, and deployment of ML models in production. This workflow is designed to ensure that the ML models run efficiently in a production environment, with proper monitoring and maintenance.
The second workflow is the Data Science Workflow, which is primarily concerned with data selection, data preparation, model research, experimentation, training, validation, tuning, and eventually model deployment. This workflow is more research-oriented and is focused on building models that can accurately predict outcomes or solve complex problems.
Both workflows are essential in the ML lifecycle, and they are supposed to work together to ensure that ML models are accurate, reliable, and effective in production.
To gain a better understanding of these two workflows, let’s take a closer look at each of them individually. Starting with Data Science, a data scientist is typically responsible for a wide range of tasks involved in building and improving ML models. They start by selecting appropriate datasets, which may come from a variety of sources, including structured and unstructured data. Data scientists then preprocess the data, which may involve cleaning the data, transforming the data, handling missing values, and feature engineering.
Once the data has been preprocessed, data scientists will typically experiment with different ML algorithms to find the best one for the given problem. This experimentation phase involves running multiple trials, fine-tuning hyperparameters, and selecting the best model based on performance metrics such as accuracy, precision, and recall. After selecting the best model, data scientists will then train and validate it using a variety of techniques, including cross-validation, to ensure that it is robust and reliable.
Moving on to DevOps, the focus is more on the production deployment of ML models. DevOps engineers are typically responsible for ensuring that the infrastructure and resources needed to deploy and run ML models in a production environment are available and properly configured. This includes managing the hardware and software resources, automating the deployment process, and monitoring the models’ performance in real-time. DevOps engineers also work closely with data scientists to ensure that the ML models can be deployed and run efficiently in production, without any performance issues or downtime.
Now as you scale, these workflows can become increasingly complex, and the disconnect between these two workflows can have an effect on the time to production. Therefore, a system needs to be in place to handle all of this in a way that people can work without getting in each other’s way, that’s where MLOps comes in. MLOps aims to bridge the gap between the development and deployment of ML models by streamlining the entire process, from data collection and preprocessing to model training, testing, and deployment.
Now that we know about these workflows, I would like you to see the diagram below and I’m sure you’ll notice an important detail here. You see, ML Code which is although the core part of the entire system is still small as compared to everything that’s needed for it to work smoothly. This is the crux of the problem that we’re trying to solve with MLOps. This was actually highlighted in the famous paper published by researchers in Google, titled Hidden Technical Debt in Machine Learning Systems
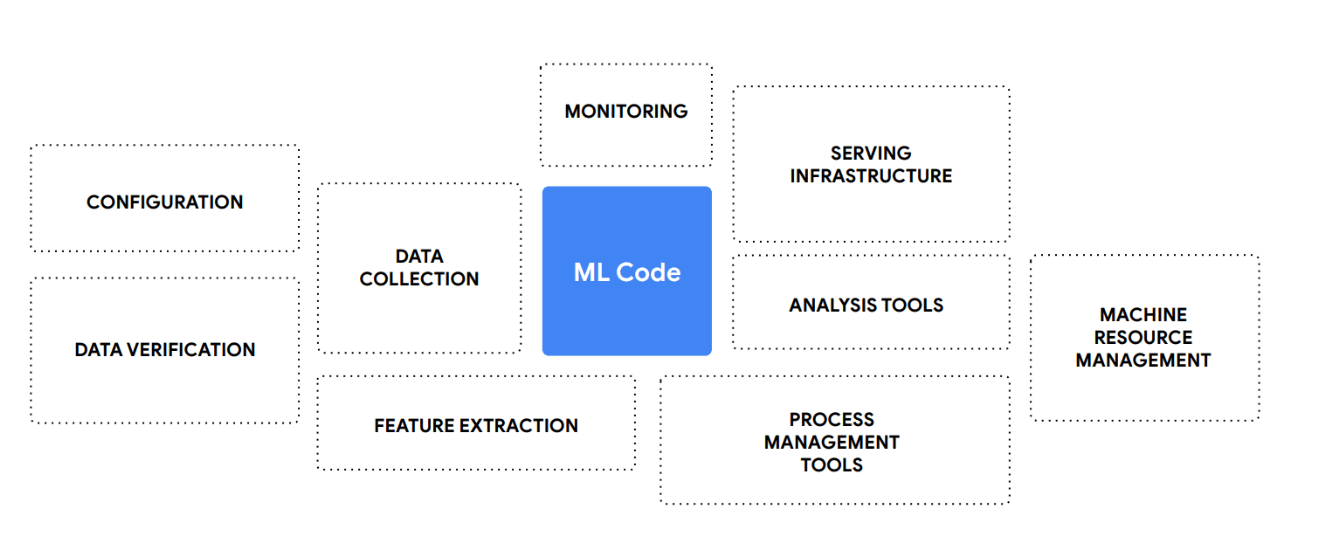
MLOps has emerged as a solution to deal with all of these complexities, by following MLOps principles we can take care of the other scaffoldings around the core machine learning part, including source code management, CI/CD, model training infrastructure, workflow orchestration, and model serving. Fortunately, a vast ecosystem of tools has emerged to support MLOps, ranging from specialized platforms to open-source solutions. A comprehensive list of major MLOps tools is available here which provides an up-to-date view of the entire ecosystem and its capabilities.

With such a wide array of tools available, organizations can choose the ones that best fit their needs, budget, and expertise. However, this abundance of choice can also be overwhelming, as it can be challenging to evaluate and compare different tools and technologies to determine which ones are most suitable for a particular project.
To address this, cloud providers such as AWS, Azure, and Google Cloud have started offering managed MLOps services that simplify the implementation and management of ML projects. These services provide a suite of tools and features that cover the entire MLOps lifecycle, from data management to model deployment and monitoring, all in one integrated environment. This approach offers several benefits, such as reduced complexity, increased scalability, and faster time to market, enabling organizations to focus on their core competencies and drive innovation.
While there are still challenges to overcome, such as standardization and governance the future of MLOps looks promising. And with the meteoric rise of AI in the recent times, it is going to become much more essential to streamline the development process and we’re all here for it.